Język polski, jak każdy język naturalny, podlega ciągłym zmianom. Badaniem tych zmian zajmują się historycy języka, którzy do niedawna dysponowali wyłącznie wyrywkowymi danymi, na podstawie których formułowali swoje hipotezy badawcze. Obecnie dostępne są duże korpusy tekstów, które można badać metodami automatycznymi. Do prowadzenia takich badań niezbędne są wyspecjalizowane narzędzia informatyczne. W ramach projektu Chronofleks powstało kilka narzędzi umożliwiających badanie zmian zachodzących w podsystemie fleksyjnym. Zmiany takie mają dwojaki charakter. Po pierwsze, mogą dotyczyć odmiany jakiegoś konkretnego leksemu, np. czasownik chrapać tworzył niegdyś formy typu chrapam, chrapasz… Po drugie, mogą dotyczyć całych kategorii gramatycznych, które wychodzą z użycia (jak np. liczba podwójna) lub pojawiają się w języku (np. rodzaj męskoosobowy).
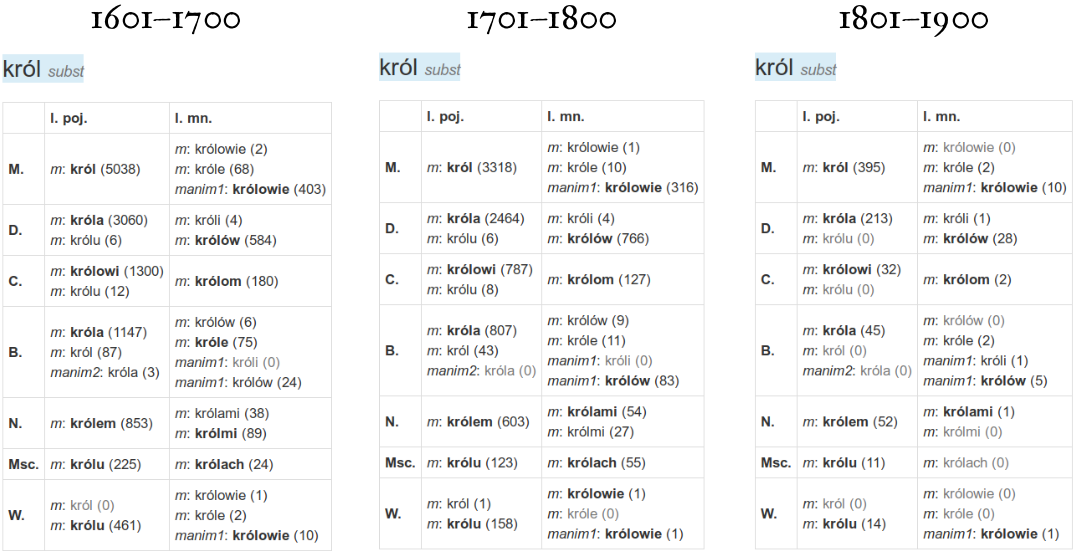
Głównym wynikiem projektu jest system komputerowy Chronofleks, który oferuje nowe spojrzenie na korpus diachroniczny, czyli uwzględniający upływ czasu. System składa się z dwóch części. Pierwszą z nich stanowi słownik fleksyjny prezentujący zmienność sposobu odmiany poszczególnych leksemów w czasie (zmiany pierwszego typu). Słownik ten prezentuje poświadczone formy odmiany, podając ich zliczenia, przy czym użytkownik ma możliwość wskazania interesującego go okresu czasu. Dzięki temu możliwe jest badanie nie tylko tego, jakie formy danych leksemów są potwierdzone, ale też ile jest tych potwierdzeń i jak są one rozłożone w czasie. Na przykład poniższa ilustracja przedstawia trzy migawki z systemu Chronofleks ukazujące formy odmiany leksemu król z tekstów z XVII, XVIII i XIX wieku. Można zaobserwować, jak zmniejsza się częstość formy królmi, która w XVII wieku dominuje nad królami, później jednak proporcje się odwracają.
Druga część systemu Chronofleks pozwala generować wykresy przedstawiające zmienność w czasie frekwencji wybranych grup form fleksyjnych lub całych kategorii (zmiany drugiego typu). Dzięki przedstawieniu na wykresie danych w postaci zagregowanej można badać niektóre zjawiska, których nie byłoby widać dla poszczególnych leksemów ze względu na zbyt małą ilość danych.
System Chronofleks został zasilony danymi z korpusu polszczyzny XVII-XVIII wieku (https://korba.edu.pl), XIX-wiecznej (http://korpus19.nlp.ipipan.waw.pl) i współczesnej (http://nkjp.pl).
Opracowanie znakowanych korpusów historycznych wymagało opracowania kilku narzędzi informatycznych. Są to: 1) tzw. transkryber, czyli program przekształcający dawny tekst z formy transliterowanej na transkrybowaną (znormalizowaną ortograficznie), 2) Anotatornia 2, czyli system wspomagający przypisywanie formom wyrazowym w tekstach wartości kategorii fleksyjnych, 3) słowniki gramatyczne (fleksyjne) dla polszczyzny XVII-XVIII-wiecznej oraz XIX-wiecznej, które stanowią podstawę działania programu zwanego analizatorem morfologicznym (dla współczesnej polszczyzny jest to system Morfeusz http://morfeusz.sgjp.pl/, a jego wariant oparty na słowniku dawnej polszczyzny – Korbeusz). Narzędzia te są dostępne dla wszystkich zainteresowanych badaczy na swobodnych licencjach, można je pobrać ze strony http://chronofleks.nlp.ipipan.waw.pl.